
Research
Our research is primarily based on investigating different Operating System modules in depth, where decision making is done based on uncertain, vague and imprecise inputs. Designing, developing and analyzing decision making algorithms based on different fuzzy inference models. These efforts will result in an Operating System that gives convenience to its users in both certain and uncertain environments and at the same time efficiently utilize the underlying hardware and software (e.g., kernel data structures and daemons) under precise as well as fuzzy conditions.
An Operating System (OS) is one of the most complex software built to manage hardware underneath a computer system. No application program can run on the computer hardware without the existence of an operating system, unless the program is self booting. An OS acts as an intermediary between the user of a computer and the computer hardware. The primary objective of this software is convenience of the user and efficient management of the underlying hardware. Different OS modules, namely, process management, memory management, file management, storage management, network management and distributed system management, work in cooperation with each other to achieve these objectives.
In a computer system, there are finite resources and competing demands. One of the main tasks that an OS performs is to allocate and de-allocate resources among the various processes competing for them in an orderly, fair, and secure manner. These resources can be hardware based (CPU cores, cache lines, memory pages, disc sectors, I/O devices, etc.) or software based (threads, processes / jobs, files, databases, etc). Some of these resources are time multiplexed (e.g., central processing unit) and some are space multiplexed (e.g., main memory) among processes. In order to perform its tasks in almost all of the above-mentioned modules, an OS has to perform decision making that is mostly based on multiple criteria under vague and imprecise conditions.
Fuzzy Systems
A computer system works on Boolean logic, in which the state of an entity / element may be ON or OFF, also referred to as true, or false. However, in many scenarios we cannot evaluate a situation to be completely true or completely false. Presently, science and technology are featured with complex processes and phenomena for which complete information is not always available. For such cases, mathematical models are developed to handle the type of systems containing elements of uncertainty. A large number of these models are based on an extension of the ordinary set theory, namely, fuzzy set theory. The notion of fuzzy sets was introduced by Zadeh as a method of representing uncertainty and vagueness. Since then, the theory of fuzzy sets has become a vigorous area of research in different disciplines, including medical and life sciences, management sciences, social sciences, engineering, statistics, graph theory, artificial intelligence, signal processing, multi-agent systems, pattern recognition, robotics, computer networks, geographical information systems, agriculture, expert systems, decision making and automata theory. Fuzzy logic is a generalization of Boolean logic that is also known as multi-valued logic, and is used in the scenarios that involve inexact and fuzzy concepts. Fuzzy logic and its extensions have been applied by researchers in a variety of areas and decision making is one of them. It uses a fuzzy-rule-base to arrive at a decision involving vague input data. Early work in fuzzy decision making was motivated by a desire to mimic the control actions of an experienced human operator and to obtain smooth interpolation between discrete outputs that would normally be obtained. Fuzzy inference is the process of formulating the mapping from a given input to an output using fuzzy logic. Fuzzy inference systems (FIS) have been successfully applied in fields such as automatic control, data classification, decision analysis, expert systems, and computer vision. Figure 1 shows the basic structure of a fuzzy inference
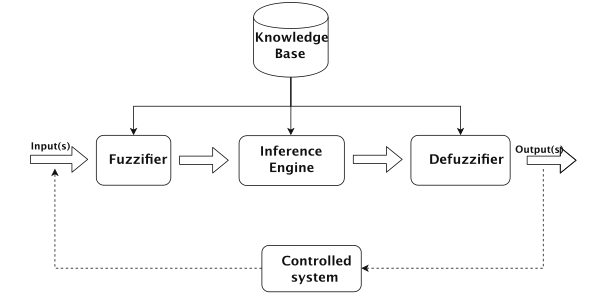
Fuzzification of Process Scheduling Algorithms
The most important hardware resource in a computer is the central processing unit (CPU). Since the era of multiprogramming, an OS allows more than one processes/threads to be loaded into the main memory. CPU scheduling is a procedure using which an OS selects a process out of a pool of ready processes to be given to the CPU for execution. There are many CPU scheduling algorithms used by general-purpose operating systems like first come first served (FCFS), shortest job first (SJF), shortest remaining time first (SRTF), priority based, round robin (RR), multi-level queue scheduling, and a combination of these algorithms. CPU scheduling is a multiple-object decision making with multiple factors like CPU utilization, throughput, turn-around time, waiting and response time.
Almost all computer resources are scheduled before use, and CPU is one of the most important and expensive resources in a computer system. Since the era of multi- programming, an operating system allows more than one process/thread to be loaded into the main memory. CPU scheduling is a procedure using which an operating system selects a process out of a pool of ready processes to be given to the CPU for execution. In an operating system, the set of rules used to determine when and how to select a new process to be run on CPU is called its scheduling policy. The scheduling policies in most modern operating systems execute processes in a round robin fashion one after another, either for a specific time quantum or until the process itself relinquish the CPU. The switching of the CPU from one process to another is known as context switch. In SCHED_RR scheduling policy, the selected process executes for a specific time quantum which is a numeric value that represents how long a process can run until it is preempted. Burst time is the amount of time that a process wants to execute before it generates an I/O request or terminates. Arrival time is the time at which a process enters in the system. Recent CPU usage is the percentage of the amount of time that a process has used CPU. Every process has an associated attribute that is called its nice value. A process can increase/decrease its nice value in order to decrease/increase its priority, respectively. Waiting time is the amount of time a process has spent waiting inside the ready queue and is computed as ‘‘finish time arrival time executed time’’. Turn-around time is the amount of time a process has spent inside the system and is computed as ‘‘finish time arrival time’’. In UNIX, schedtool is a utility that is used to query, set, and execute processes according to various scheduling policies. For example, in order to query the scheduling parameters/attributes of a process with PID 8991, we can use following command on a UNIX shell:
$ schedtool 8991
PID 8991: PRIO 0, POLICY N: SCHED_NORMAL, NICE 0, AFFINITY 0x1
The static priority of above process is zero, and its scheduling policy is SCHED_NORMAL, with a default nice value of zero and process affinity mask of 0x1. The process affinity is a bit mask showing on what all CPUs this process can execute. We can also use schedtool to check what all different scheduling policies are supported on our UNIX machine. When run on our Linux machine, this utility shows that our machine supports two real time (SCHED_FIFO and SCHED_RR) and four conventional scheduling policies as shown below:
$ schedtool -r
N: SCHED_NORMAL: prio_min 0, prio_max 0
F: SCHED_FIFO: prio_min 1, prio_max 99
R: SCHED_RR: prio_min 1, prio_max 99
B: SCHED_BATCH: prio_min 0, prio_max 0
I: SCHED_ISO: policy not implemented
D: SCHED_IDLEPRIO: prio_min 0, prio_max 0
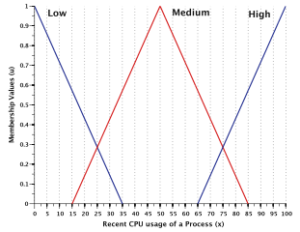
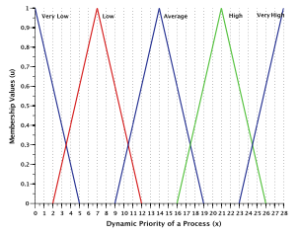
The basic structure of a fuzzy decision-making system for CPU scheduler is shown in Fig. 2. It is a three- input and one-output fuzzy inference system. The three inputs are the burst time, nice value and recent CPU usage of all the processes in run queue. The two attributes, namely burst time and nice value, are read from an input file, while the third attribute, recent CPU usage, is calculated using a formula. The three input parameters are fuzzified and then passed to the fuzzy inference engine comprised of twenty-seven fuzzy rules. The output of the fuzzy inference engine is later defuzzified to a crisp value which is the dynamic priority of the processes.
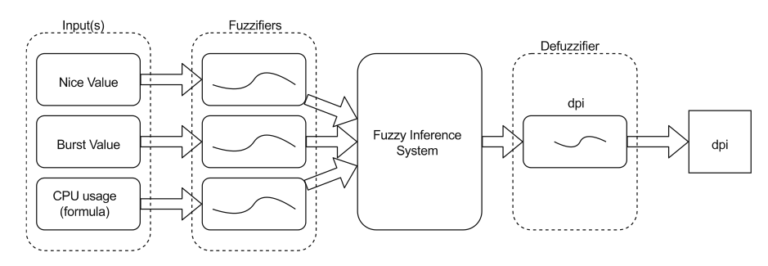
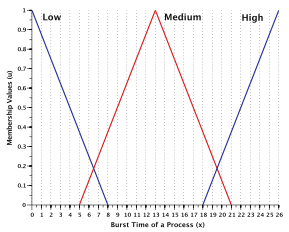
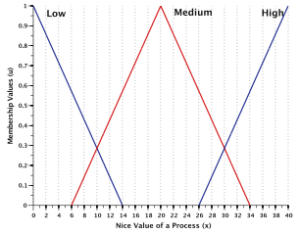
The Fuzzifier component is responsible for fuzzifying the three input parameters, namely the burst time, nice value, and recent CPU usage of every runnable process. It determines the degree to which these inputs belong to each of the appropriate fuzzy sets. Following triangular membership functions can be used for mapping a crisp input value to a fuzzy membership value between 0 and 1. The following triangular membership functions can be used for mapping a crips input value to a fuzzy membership value for the three input parameters and the output parameter.
Fuzzification of Memory Allocation algorithms
After CPU, the second most important resource in a computer system is random access memory (RAM), normally called main memory, in which executable programs are loaded for execution. Decisions are needed to be taken by the OS as to when to load a program into memory, where to load it, how much of it to load, the time to load it, and should it be loaded when the user asks for it or should the OS forecast its load time? If the memory is not sufficient for a new process or part of an existing process to be loaded, one or more processes need to be selected to be swapped out on secondary storage.
Fuzzification of Disk Scheduling algorithms
The most common secondary storage device used by general purpose computers is a disk. On a disk, from a user’s point of view a file is the smallest unit of allocation. A file system on a storage device is an OS module that manages the storage and retrieval of data on the storage medium. The two main components involved in accessing data from a disk are rotational delay and seek time. There are many algorithms that are used to reduce the seek time and rotational delay like First Come First Served (FCFS), Shortest Seek Time First (SSTF), Scan, Look, Circular Scan (C-SCAN), Circular Look (C-LOOK). Two requests might arrive at a time for reading data from two sectors which are at same distance from the read/write head of the disk. Thus, decision making is required to select the sector which need to be served before the other. There are a variety of file systems in use these days like ntfs, ext3, ext4, raiserfs, zfs, etc. that differ in their storage structure, size of files they support, security, integrity, means of searching files according to different parameters, and so on. Fuzzy techniques can be applied in designing and developing fuzzy algorithms for performing these tasks.
Fuzzification of Distributed Systems
A distributed system is a software system in which components located on networked computers communicate and coordinate their actions by passing messages. In this regard an OS has to decide as to on which node a process should execute and on which node input data should be placed to achieve maximum performance. One of the main tasks in network management is routing, i.e., the selection of best path on a network from the source node to the destination node. This is also a multiple-object decision making problem with factors like path cost, network delay, load, maximum transmission unit, reliability and network bandwidth. Some famous routing algorithms are distance vector, path vector, and link state. Fuzzy algorithms can be applied to redesign these algorithms to achieve better performance.